

说明: n:数据规模 k:“桶”的个数 In-place:占用常数内存,不占用额外内存 Out-place:占用额外内存 稳定性:排序后2个相等键值的顺序和排序之前它们的顺序相同
冒泡排序(Bubble Sort)
冒泡排序每次找出一个最大的元素,因此需要遍历 n-1 次。还有一种优化算法,就是立一个flag,当在一趟序列遍历中元素没有发生交换,则证明该序列已经有序。但这种改进对于提升性能来说并没有什么太大作用。
当输入的数据已经是正序时。时间复杂度最优为O(n) 当输入的数据是反序时,时间复杂度最差为O(n^2)。 冒泡排序 Python 代码实现:
def bubbleSort(nums):
for i in range(len(nums) - 1): # 遍历 len(nums)-1 次
for j in range(len(nums) - i - 1): # 已排好序的部分不用再次遍历
if nums[j] > nums[j+1]:
nums[j], nums[j+1] = nums[j+1], nums[j] # Python 交换两个数不用中间变量
return nums
选择排序(Selection Sort)
选择排序不受输入数据的影响,即在任何情况下时间复杂度不变。选择排序每次选出最小的元素,因此需要遍历 n-1 次。
选择排序 Python 代码实现:
def selectionSort(nums):
for i in range(len(nums) - 1): # 遍历 len(nums)-1 次
minIndex = i
for j in range(i + 1, len(nums)):
if nums[j] < nums[minIndex]: # 更新最小值索引
minIndex = j
nums[i], nums[minIndex] = nums[minIndex], nums[i] # 把最小数交换到前面
return nums
插入排序(Insertion Sort)
插入排序如同打扑克一样,每次将后面的牌插到前面已经排好序的牌中。插入排序有一种优化算法,叫做拆半插入。因为前面是局部排好的序列,因此可以用折半查找的方法将牌插入到正确的位置,而不是从后往前一一比对。折半查找只是减少了比较次数,但是元素的移动次数不变,所以时间复杂度仍为 O(n^2) !
插入排序 Python 代码实现:
def insertionSort(nums):
for i in range(len(nums) - 1): # 遍历 len(nums)-1 次
curNum, preIndex = nums[i+1], i # curNum 保存当前待插入的数
while preIndex >= 0 and curNum < nums[preIndex]: # 将比 curNum 大的元素向后移动
nums[preIndex + 1] = nums[preIndex]
preIndex -= 1
nums[preIndex + 1] = curNum # 待插入的数的正确位置
return nums
希尔排序(Shell Sort)
希尔排序是插入排序的一种更高效率的实现。它与插入排序的不同之处在于,它会优先比较距离较远的元素。
比如对于待排序列 {44,12,59,36,62,43,94,7,35,52,85},我们可设定增量序列为 {5,3,1}。第一个增量为 5,因此 {44,43,85}、{12,94}、{59,7}、{36,35}、{62,52} 分别隶属于同一个子序列,子序列内部进行插入排序;然后选取第二个增量3,因此 {43,35,94,62}、{12,52,59,85}、{7,44,36} 分别隶属于同一个子序列;最后一个增量为 1,这一次排序相当于简单插入排序,但是经过前两次排序,序列已经基本有序,因此此次排序时间效率就提高了很多。
希尔排序的核心在于间隔序列的设定。既可以提前设定好间隔序列,也可以动态的定义间隔序列。动态定义间隔序列的算法是《算法(第4版》的合著者 Robert Sedgewick 提出的。
希尔排序 Python 代码实现:
def shellSort(nums):
lens = len(nums)
gap = 1
while gap < lens // 3:
gap = gap * 3 + 1 # 动态定义间隔序列
while gap > 0:
for i in range(gap, lens):
curNum, preIndex = nums[i], i - gap # curNum 保存当前待插入的数
while preIndex >= 0 and curNum < nums[preIndex]:
nums[preIndex + gap] = nums[preIndex] # 将比 curNum 大的元素向后移动
preIndex -= gap
nums[preIndex + gap] = curNum # 待插入的数的正确位置
gap //= 3 # 下一个动态间隔
return nums
归并排序(Merge Sort)
作为一种典型的分而治之思想的算法应用,归并排序的实现由两种方法:
自上而下的递归(所有递归的方法都可以用迭代重写,所以就有了第2种方法)
自下而上的迭代
和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是O(n log n)的时间复杂度。代价是需要额外的内存空间。
归并排序 Python 代码实现:
def mergeSort(nums):
# 归并过程
def merge(left, right):
result = [] # 保存归并后的结果
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result = result + left[i:] + right[j:] # 剩余的元素直接添加到末尾
return result
# 递归过程
if len(nums) <= 1:
return nums
mid = len(nums) // 2
left = mergeSort(nums[:mid])
right = mergeSort(nums[mid:])
return merge(left, right)
快速排序(Quick Sort)
又是一种分而治之思想在排序算法上的典型应用。本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。它是处理大数据最快的排序算法之一,虽然 Worst Case 的时间复杂度达到了 O(n²),但是在大多数情况下都比平均时间复杂度为 O(n log n) 的排序算法表现要更好,因为 O(n log n) 记号中隐含的常数因子很小,而且快速排序的内循环比大多数排序算法都要短小,这意味着它无论是在理论上还是在实际中都要更快,比复杂度稳定等于 O(n log n) 的归并排序要小很多。所以,对绝大多数顺序性较弱的随机数列而言,快速排序总是优于归并排序。它的主要缺点是非常脆弱,在实现时要非常小心才能避免低劣的性能。
快速排序 Python 代码实现:
def quickSort(nums): # 这种写法的平均空间复杂度为 O(nlogn)
if len(nums) <= 1:
return nums
pivot = nums[0] # 基准值
left = [nums[i] for i in range(1, len(nums)) if nums[i] < pivot]
right = [nums[i] for i in range(1, len(nums)) if nums[i] >= pivot]
return quickSort(left) + [pivot] + quickSort(right)
'''
@param nums: 待排序数组
@param left: 数组上界
@param right: 数组下界
'''
def quickSort2(nums, left, right): # 这种写法的平均空间复杂度为 O(logn)
# 分区操作
def partition(nums, left, right):
pivot = nums[left] # 基准值
while left < right:
while left < right and nums[right] >= pivot:
right -= 1
nums[left] = nums[right] # 比基准小的交换到前面
while left < right and nums[left] <= pivot:
left += 1
nums[right] = nums[left] # 比基准大交换到后面
nums[left] = pivot # 基准值的正确位置,也可以为 nums[right] = pivot
return left # 返回基准值的索引,也可以为 return right
# 递归操作
if left < right:
pivotIndex = partition(nums, left, right)
quickSort2(nums, left, pivotIndex - 1) # 左序列
quickSort2(nums, pivotIndex + 1, right) # 右序列
return nums
堆排序(Heap Sort)
堆排序可以说是一种利用堆的概念来排序的选择排序。分为两种方法:
大根堆:每个节点的值都大于或等于其子节点的值,用于升序排列;
小根堆:每个节点的值都小于或等于其子节点的值,用于降序排列。
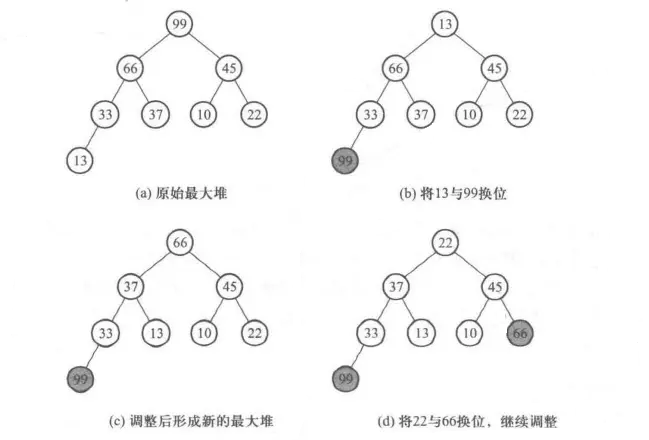
如下图所示,首先将一个无序的序列生成一个最大堆,如图(a)所示。接下来我们不需要将堆顶元素输出,只要将它与堆的最后一个元素对换位置即可,如图(b)所示。这时我们确知最后一个元素 99 一定是递增序列的最后一个元素,而且已经在正确的位置上。 现在问题变成了如何将剩余的元素重新生成一个最大堆——也很简单,只要依次自上而下进行过滤,使其符合最大堆的性质。图(c)是调整后形成的新的最大堆。要注意的是,99 已经被排除在最大堆之外,即在调整的时候,堆中元素的个数应该减 1 。结束第 1 轮调整后,再次将当前堆中的最后一个元素 22 与堆顶元素换位,如图(d)所示,再继续调整成新的最大堆……如此循环,直到堆中只剩 1 个元素,即可停止,得到一个从小到大排列的有序序列。
堆排序 Python 代码实现:
# 大根堆(从小打大排列)
def heapSort(nums):
# 调整堆
def adjustHeap(nums, i, size):
# 非叶子结点的左右两个孩子
lchild = 2 * i + 1
rchild = 2 * i + 2
# 在当前结点、左孩子、右孩子中找到最大元素的索引
largest = i
if lchild < size and nums[lchild] > nums[largest]:
largest = lchild
if rchild < size and nums[rchild] > nums[largest]:
largest = rchild
# 如果最大元素的索引不是当前结点,把大的结点交换到上面,继续调整堆
if largest != i:
nums[largest], nums[i] = nums[i], nums[largest]
# 第 2 个参数传入 largest 的索引是交换前大数字对应的索引
# 交换后该索引对应的是小数字,应该把该小数字向下调整
adjustHeap(nums, largest, size)
# 建立堆
def builtHeap(nums, size):
for i in range(len(nums)//2)[::-1]: # 从倒数第一个非叶子结点开始建立大根堆
adjustHeap(nums, i, size) # 对所有非叶子结点进行堆的调整
# print(nums) # 第一次建立好的大根堆
# 堆排序
size = len(nums)
builtHeap(nums, size)
for i in range(len(nums))[::-1]:
# 每次根结点都是最大的数,最大数放到后面
nums[0], nums[i] = nums[i], nums[0]
# 交换完后还需要继续调整堆,只需调整根节点,此时数组的 size 不包括已经排序好的数
adjustHeap(nums, 0, i)
return nums # 由于每次大的都会放到后面,因此最后的 nums 是从小到大排列
计数排序(Counting Sort)
计数排序要求输入数据的范围在 [0,N-1] 之间,则可以开辟一个大小为 N 的数组空间,将输入的数据值转化为键存储在该数组空间中,数组中的元素为该元素出现的个数。它是一种线性时间复杂度的排序。
计数排序 Python 代码实现:
def countingSort(nums):
bucket = [0] * (max(nums) + 1) # 桶的个数
for num in nums: # 将元素值作为键值存储在桶中,记录其出现的次数
bucket[num] += 1
i = 0 # nums 的索引
for j in range(len(bucket)):
while bucket[j] > 0:
nums[i] = j
bucket[j] -= 1
i += 1
return nums
桶排序(Bucket Sort)
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。
为了使桶排序更加高效,我们需要做到这两点:
在额外空间充足的情况下,尽量增大桶的数量
使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中
同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。
当输入的数据可以均匀的分配到每一个桶中,此时为最优时间复杂度
当输入的数据被分配到了同一个桶中,此时为最优时间复杂度
桶排序 Python 代码实现:
def bucketSort(nums, defaultBucketSize = 5):
maxVal, minVal = max(nums), min(nums)
bucketSize = defaultBucketSize # 如果没有指定桶的大小,则默认为5
bucketCount = (maxVal - minVal) // bucketSize + 1 # 数据分为 bucketCount 组
buckets = [] # 二维桶
for i in range(bucketCount):
buckets.append([])
# 利用函数映射将各个数据放入对应的桶中
for num in nums:
buckets[(num - minVal) // bucketSize].append(num)
nums.clear() # 清空 nums
# 对每一个二维桶中的元素进行排序
for bucket in buckets:
insertionSort(bucket) # 假设使用插入排序
nums.extend(bucket) # 将排序好的桶依次放入到 nums 中
return nums
基数排序(Radix Sort)
基数排序是桶排序的一种推广,它所考虑的待排记录包含不止一个关键字。例如对一副牌的整理,可将每张牌看作一个记录,包含两个关键字:花色、面值。一般我们可以将一个有序列是先按花色划分为四大块,每一块中又再按面值大小排序。这时“花色”就是一张牌的“最主位关键字”,而“面值”是“最次位关键字”。
基数排序有两种方法:
MSD (主位优先法):从高位开始进行排序
LSD (次位优先法):从低位开始进行排序
基数排序 Python 代码实现:
# LSD Radix Sort
def radixSort(nums):
mod = 10
div = 1
mostBit = len(str(max(nums))) # 最大数的位数决定了外循环多少次
buckets = [[] for row in range(mod)] # 构造 mod 个空桶
while mostBit:
for num in nums: # 将数据放入对应的桶中
buckets[num // div % mod].append(num)
i = 0 # nums 的索引
for bucket in buckets: # 将数据收集起来
while bucket:
nums[i] = bucket.pop(0) # 依次取出
i += 1
div *= 10
mostBit -= 1
return nums
补充:外部排序 外部排序是指大文件排序,即待排序的数据记录以文件的形式存储在外存储器上。由于文件中的记录很多、信息容量庞大,所以整个文件所占据的存储单元往往会超过了计算机的内存量,因此,无法将整个文件调入内存中进行排序。于是,在排序过程中需进行多次的内外存之间的交换。在实际应用中,由于使用的外设不一致,通常可以分为磁盘文件排序和磁带文件排序两大类。
外部排序基本上由两个相对独立的阶段组成。首先,按可用内存大小,将外存上含 N 个记录的文件分成若干长度为 L(<N) 的子文件,依次读入内存,利用内部排序算法进行排序。然后,将排序后的文件写入外存,通常将这些文件称为归并段(Run)或“顺串”;对这些归并段进行逐步归并,最终得到整个有序文件。可见外部排序的基本方法是归并排序法,下面的例子给出了一个简单的外部排序解决过程。
比如给定磁盘上有6大块记录需要排序,而计算机内存最多只能对3个记录块进行内排序,则外部排序的过程如下图所示。
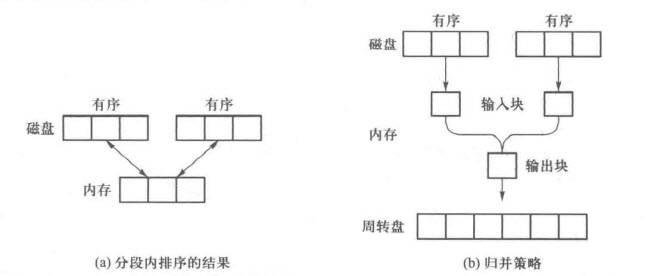
首先将连续的3大块记录读入内存,用任何一种内部排序算法完成排序,再写回磁盘。经过2次3大块记录的内部排序,得到上图(a)的结果。然后另用一个可容纳6大块记录的周转盘,辅助最后的归并。方法是将内存分成3块,其中2块用于输入,1块用于输出,指定一个输入块只负责读取一个归并段中的记录,如上图(b)所示。归并步骤为:
当任一输入块为空时,归并暂停,将相应归并段中的一块信息写入内存
将内存中2个输入块中的记录逐一归并入输出块
当输出块写满时,归并暂停,将输出块中的记录写入周转盘
如此可将2个归并段在周转盘上归并成一个有序的归并段。上例的解决方法是最简单的归并法,事实上外部排序的效率还可以进一步提高。要提高外排的效率,关键要解决以下4个问题:
1. 如何减少归并轮数
2. 如何有效安排内存中的输入、输出块,使得机器的并行处理能力被最大限度利用
3. 如何有效生成归并段
4. 如何将归并段进行有效归并
针对这四大问题,人们设计了多种解决方案,例如釆用多路归并取代简单的二路归并,就可以减少归并轮数;例如在内存中划分出2个输出块,而不是只用一个,就可以设计算法使得归并排序不会因为磁盘的写操作而暂停,达到归并和写周转盘同时并行的效果;例如通过一种“败者树”的数据结构,可以一次生成2倍于内存容量的归并段;例如利用哈夫曼树的贪心策略选择归并次序,可以耗费最少的磁盘读写时间等。
其他一些比较: 基数排序 vs 计数排序 vs 桶排序 这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异: 基数排序:根据键值的每位数字来分配桶 计数排序:每个桶只存储单一键值 桶排序:每个桶存储一定范围的数值
哪些排序算法可以在未结束排序时找出第 k 大元素? 冒泡、选择、堆排序、快排
| 排序算法 | 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 | 排序方式 | 稳定性 |
|---|---|---|---|---|---|---|
| 冒泡排序 | O(n2) | O(n) | O(n2) | O(1) | in-palce | 稳定 |
| 选择排序 | O(n2) | O(n2) | O(n2) | O(1) | in-place | 不稳定 |
| 插入排序 | O(n2) | O(n) | O(n2) | O(1) | in-palce | 稳定 |
| 希尔排序 | O(nlogn) | O(nlog2n) | O(nlog2n) | O(1) | in-place | 不稳定 |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | o(n) | out-place | 稳定 |
| 快速排序 | O(nlogn) | O(nlogn) | O(n2) | O(logn) | in-place | 不稳定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | in-place | 不稳定 |
| 计数排序 | O(n+k) | O(n+k) | O(n+k) | O(k) | out-place | 稳定 |
| 桶排序 | O(n+k) | O(n+k) | O(n2) | O(n+k) | out-place | 稳定 |
| 基数排序 | O(nxk) | O(nxk) | O(nxk) | O(nxk) | out-place | 稳定 |
本文链接:http://nix.pub/article/sort/

